CogBench Benchmarking Cognitive Alignment of Large Language Models in Educational Question Answering
Apr 10, 2026·
 ·
2 min read
·
2 min read
Tong Lu
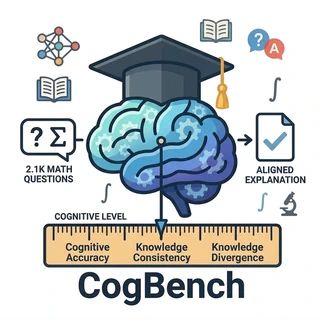
🚀 Introduction
CogBench is a benchmark to assess the cognitive alignment capabilities of Large Language models in educational question answering
## 🔥 Highlights- Benchmark: 2,100 K–12 mathematics questions, each with multiple valid, cognition-differentiated solutions
- Average 2.16 solutions per question; 3.2 curriculum knowledge components per question
- Grade coverage: Primary 40%, Middle 35%, High 25%
- 3 cognition-aware QA tasks; 3 complementary metrics (CA, KC, KD)
- Curriculum-Aware Knowledge Graph (CAKG) aligned to grade levels and solution strategies
- Evaluated 11 LLMs (open-source and proprietary) via APIs (Sept–Dec 2025)
- Key findings:
- Large gap between standard accuracy (up to 0.942) and cognitive alignment under unconstrained QA (best CA 0.534, KC 0.604)
- Grade-constrained prompting improves alignment (best CA 0.560, KC 0.753; KD up to 0.790)
- Knowledge-constrained prompting often reduces alignment due to activation of higher-level parametric patterns
- Fine-tuning (SFT + DPO) improves CA (0.47→0.63) and KC (0.54→0.68) with slight drops in ACC (0.88→0.83) and KD (0.72→0.61)
- Automatic metrics correlate well with expert human judgments on consistency and diversity
🔥 Framework

📊 Dataset & Annotations
- Sources: 1.2K Olympiad problems (public website) + 0.9K CMMath problems
- Coverage: Primary (Grades 1–6), Middle (7–9), High (10–12)
- Per-question: at least two solutions at different cognitive levels
- Generation base model for multi-solution sampling: Qwen3-30B-A3B
- Expert alignment: education experts verify solution–knowledge–grade mapping
- Reliability: high-quality, cognition-aware labels after expert review
📦 Usage
The evaluation program is in the evaluation folder, and the metrics it uses are in the metric folder.
Three prompting modes:
- Unconstrained:
response1_title_only - Grade-constrained:
response2_title_grade - Knowledge-Constrained:
response3_title_knowledge
Run the evaluation scripts:
python -m evaluation.response --model_name gpt-5-nano-2025-08-07
python -m evaluation.evaluate_response --model_name gpt-5-nano-2025-08-07
python -m evaluation.find_knowledge_used --model_name gpt-5-nano-2025-08-07
python -m evaluation.calculate_metrics --model_name gpt-5-nano-2025-08-07
📄 Citation
If you use Cogbench or our construction framework, please cite:
@article{CogBench2026,
title={CogBench: Benchmarking Cognitive Alignment of Large Language Models in Educational Question Answering},
author={Tong Lu, Zhichun Wang, Yuanhao Sun, Yaoyu Zhou, Mingrui Li,Yiming Guan, Zhiyong Bai},
year={2026},
journal={Findings of ACL}
}

Authors
PhD candidate
I am a second year Ph.D. candidate in the School of Artificial Intelligence at Beijing Normal University, Beijing, China.
I obtained a Bachelor of Science degree from Hebei GEO University and a Master of Engineering degree from Yunnan University.
Now, I engage in research related to the field of natural language processing.